Research
Over the past decade, advancements in learning-based systems have transformed industries, from scientific data processing to commercial applications. These achievements stem from innovations in algorithms, increased computational power, and system designs. Dr. Mao's current research focuses on Scalable Computing Systems, addressing challenges in both classical and quantum domains. The following figure presents a summary of my research. Our team aims to push the boundaries of quantum-classical computing through resource-efficient algorithms, novel architectures, and system-level optimizations, with a vision to enhance both academic research and real-world applications.
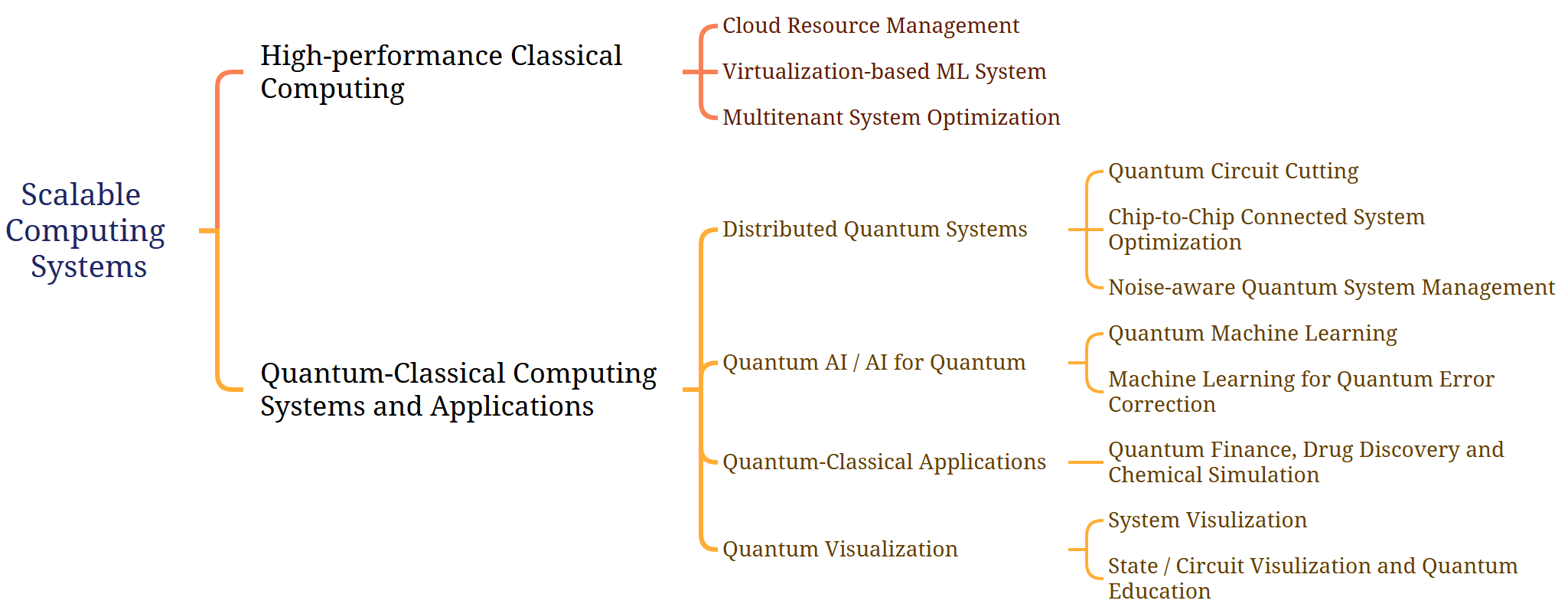
Quantum-Classical Computing Systems and Applications
As the limits of classical computing become apparent in the post-Moore’s Law era, quantum computing offers a transformative alternative. Platforms like IBM-Q, Amazon Braket, and Microsoft Azure have opened new avenues for exploring quantum-classical synergies. My research focuses on leveraging quantum computing to address the challenges of model scalability and resource constraints in deep learning.
- In the NISQ era, quantum computing faces significant constraints, including limited qubit availability, noise-prone devices, and inefficient single-tenant architectures. These limitations often lead to underutilized resources, long wait times, and restricted access to quantum capabilities. To address these challenges, my future research will focus on developing a multi-tenant quantum cloud system that incorporates circuit-cutting techniques and Kubernetes-based infrastructure. Circuit cutting enables the decomposition of large quantum circuits into smaller subcircuits that can be executed on resource-constrained quantum devices. This approach allows more efficient use of available hardware by enabling complex algorithms to run on smaller quantum systems, overcoming current scalability limitations. To further enhance efficiency, we integrate ML-based scheduling algorithms that leverage historical and real-time workload data to predict optimal task placements at each qubit’s level. These models will dynamically allocate qubits, maximizing throughput and minimizing contention in a shared environment. Together, these innovations aim to lower the barriers to quantum accessibility, enabling scalable, high-performance quantum cloud systems for diverse applications while making quantum computing more efficient and practical in the near term.
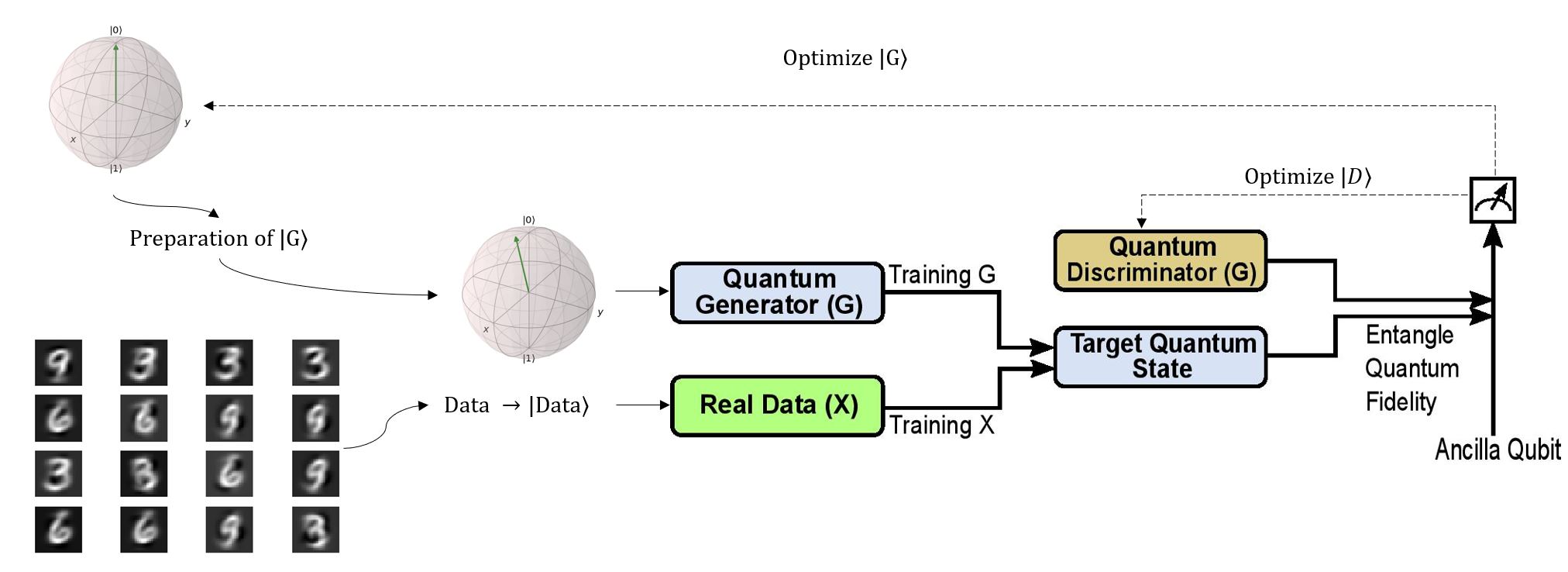
- From a practical system point of view, we proposed QuClassi, a hybrid quantum-classical deep neural network architecture for classification problems (e.g. face recognition). With a limited number of qubits, our novel system is able to reduce 95% of the size of the classic learning models. To the best of our knowledge, QuClassi is the first practical solution that tackles image classification problems in the quantum setting. Additionally, comparing QuClassi to the other similarly parameterized classical neural networks, QuClassi outperformed them by learning significantly faster (up to 53%) and achieved up to 215% higher accuracy in our experiments. Besides experiments on local simulators, we conducted our experiments on real quantum computers, IBM-Q Experience, to evaluate the proposed system.
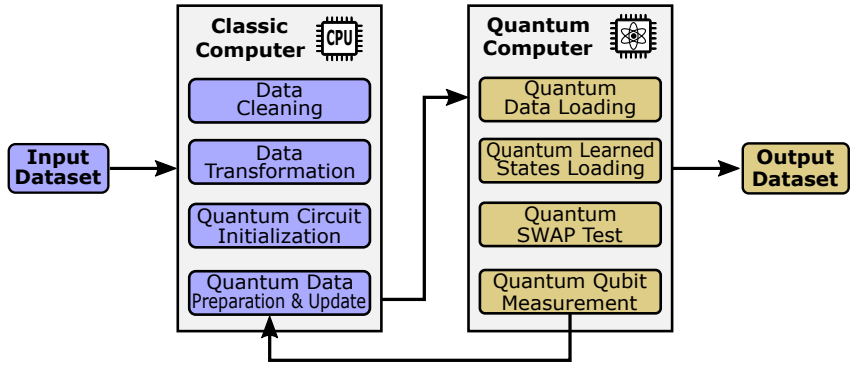
High-performance Classical Computing Systems
The rapid growth of deep learning and big data analytics has created a pressing demand for high-performance computing systems. These systems power decision-making processes by efficiently analyzing large datasets using sophisticated scheduling algorithms. However, effectively distributing containers across physical hosts remains a significant challenge. My contributions to this field, detailed in publications, focus on optimizing system performance for containerized deep-learning applications. A key achievement is FlowCon (i.e. published on IEEE Transaction on Cloud Computing (TCC) 2022), a system for managing virtualized container clusters tailored for distributed workloads. Tested on Google Cloud, FlowCon has reduced completion times by 68.8% and overall makespan by 18%. Building on this foundation, we developed DQoES (Differentiated Quality of Experience Scheduling, another publication in TCC 2022) for deep learning applications. DQoES dynamically adjusts resource allocation to meet clients’ QoE targets, ensuring satisfying user experiences. Experiments have shown its adaptability across workloads, achieving up to 8x more satisfied models compared to existing systems.